
前言
告别繁琐的手动收集!这款 Bilibili (B站) 评论数据采集工具,让您轻松获取任一视频的全部一级评论及其二级回复。仅需提供 BV 号,系统将自动识别视频并抓取丰富的用户数据,包括用户基础信息、评论详情、IP 归属地、头像链接、会员状态和等级等,并以结构化的 CSV 格式导出,方便快捷进行后续分析。
一:Bilibili 评论爬虫核心特性
1. 深度数据采集
多级评论全覆盖: 彻底支持爬取所有一级评论以及其下的全部二级回复,确保数据完整性。
详尽用户信息画像: 精准采集用户 ID、用户名、等级、性别、IP 属地、大会员状态等关键信息,助力用户画像分析。
2. 自动化与便捷
评论自动分页处理: 脚本自动遍历所有评论页面,完全无需手动干预分页或循环操作。
标准 CSV 格式导出: 采集结果直接保存为 CSV 文件,原生兼容 Excel 和主流数据分析工具,方便快捷。
3. 稳定可靠机制
增强型反爬处理: 采用时间戳和 MD5 加密等机制生成请求参数,有效模拟真实用户行为,显著降低被封禁风险,确保长期稳定运行。
二:快速部署
1:配置Cookie
登录B站,然后按F12打开开发者模式,点击网络,在搜索框中搜索Cookie,就可以在下方的显示栏选中Cookie,在项目根目录创建bili_cookie.txt文件,将Cookie粘贴进去.
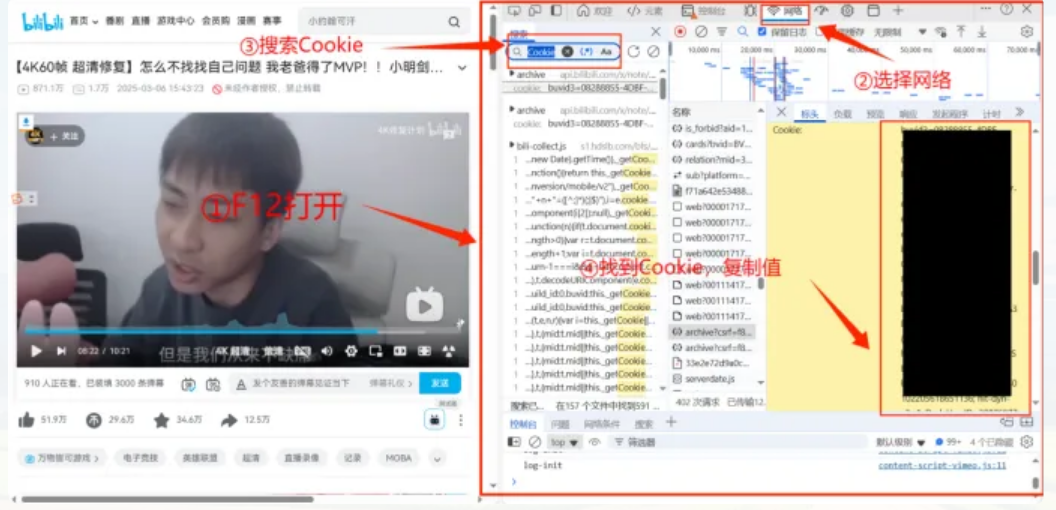
同理,搜索User-Agent,复制该值到代码中的Header里。
## 获取B站的Header
def get_Header():
with open('bili_cookie.txt','r') as f:
cookie=f.read()
header={
"Cookie":cookie,
"User-Agent":'这里是User-Agent值'
}2:运行脚本
1.修改脚本中的目标视频BV号(代码末尾的 bv = "BV1hMo4YrEW4")。
2.执行脚本
注意:is_second(默认开启):设为True时爬取二级评论,False仅爬取一级评论。
自定义请求头:修改get_Header()中的User-Agent以模拟不同浏览器环境。
三:核心原理
1:网络分析
经过抓包分析,我们确认 Bilibili (B站) 网页端的评论是通过请求特定的 URL 并返回 JSON 格式的数据实现的。前端仅负责解析和渲染这些数据。因此,我们的爬虫绕过了复杂的前端渲染流程,直接模拟网页请求来截取原始的 JSON 评论数据。 这种方法极大地提高了数据获取的效率和准确性,是实现评论数据高效爬取的关键。
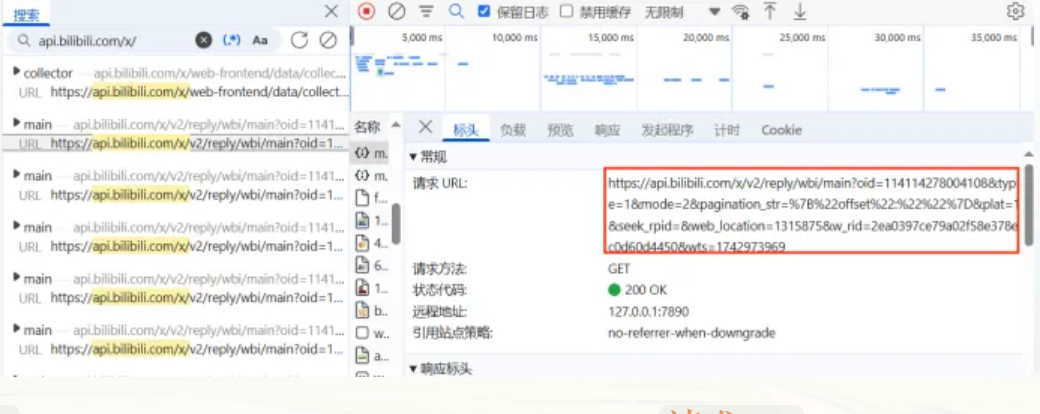
分页抓取机制: B 站的评论数据采取分页加载模式,每一个请求 URL 大约仅包含 20 条评论记录。因此,为了确保爬取到视频下的所有评论数据,爬虫将自动识别和持续访问全部的分页请求 URL,直到数据流末尾,最终汇总成完整的评论数据集。
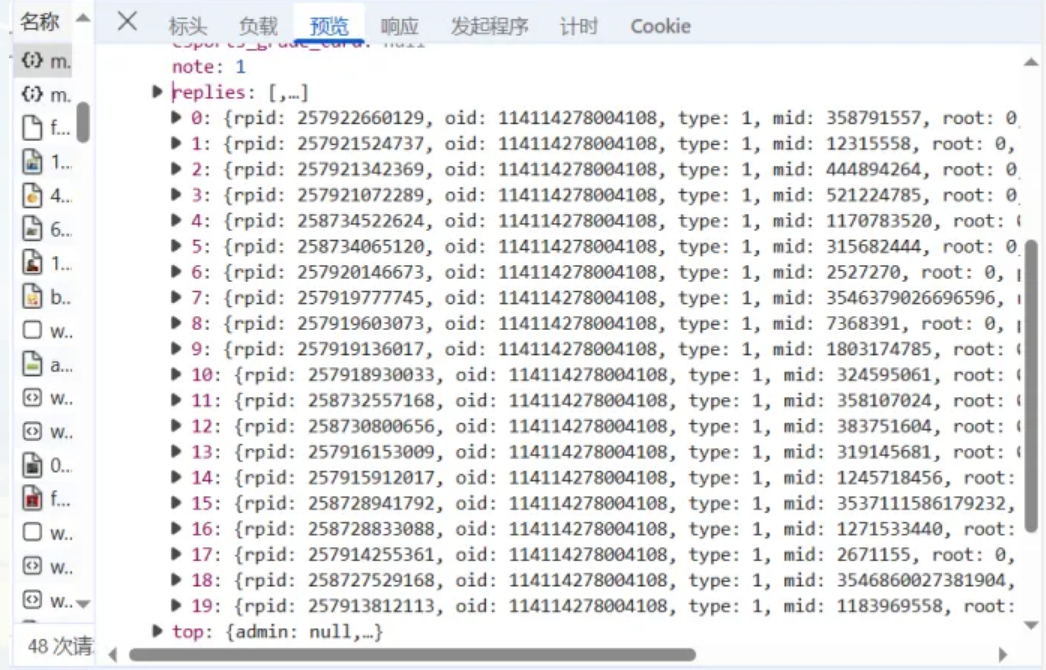
动态参数驱动: 我们观察到请求 URL 中的链接参数与当前请求的**数据负载(Payload)**直接相关。每一个请求 URL 都携带独有的、动态生成的参数。通过精确地识别和处理这些参数,爬虫程序能够准确构造并访问下一个分页 URL,从而实现对所有评论页的顺序访问和数据遍历。
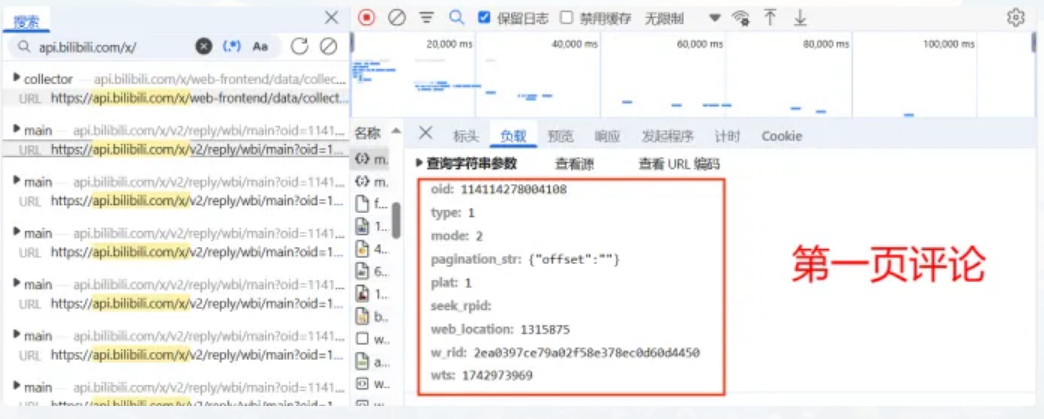
总结而言,要实现 B 站视频全量评论数据的获取,核心工作就在于:精确地捕获和识别每一页请求 URL 中的动态参数。
只有通过获取这些不断变化的参数,才能成功构造出后续的分页请求 URL,从而实现对所有评论数据的无缝、连续采集。
2: oid的获取
OID 参数关联: 在 Bilibili 的数据结构中,每个视频都有一个独一无二的 oid 值作为其身份标识。
我们通过特定的函数调用,能够根据 BV 号自动解析并获取到该视频的 oid 值。利用此 oid,爬虫即可进一步获取并关联该视频的准确标题和评论数据。
## 通过bv号,获取视频的oid
def get_information(bv):
resp = requests.get(f"https://www.bilibili.com/video/{bv}",headers=get_Header())
## 提取视频oid
obj = re.compile(f'"aid":(?P<id>.*?),"bvid":"{bv}"')
oid = obj.search(resp.text).group('id')
## 提取视频的标题
obj = re.compile(r'<title data-vue-meta="true">(?P<title>.*?)</title>')
title = obj.search(resp.text).group('title')
return oid, title3: type、plat、mode以及seek_rpid
type、plat和mdoe都是常量,分别为1、1和2。同时seek_rpid的值也默认为空
## 参数
mode = 2
plat = 1
type = 1
seek_rpid=''4: web_location
web_location的值也默认是2314675,如果不放心或者报错,则可以按照上述方法查看自己的web_location值
web_location = 23146755 :wts的获取
从名字就可以看出来wts是当下的时间戳,对于这个,可以调用time,获取现在的时间戳。
## 获取当下时间戳
wts = time.time()6: pagination_str 的提取
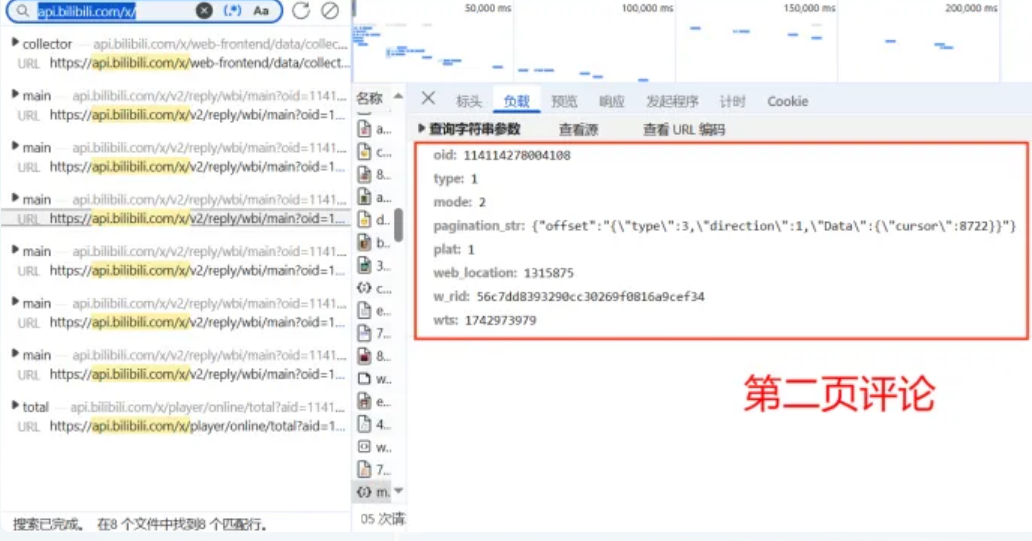
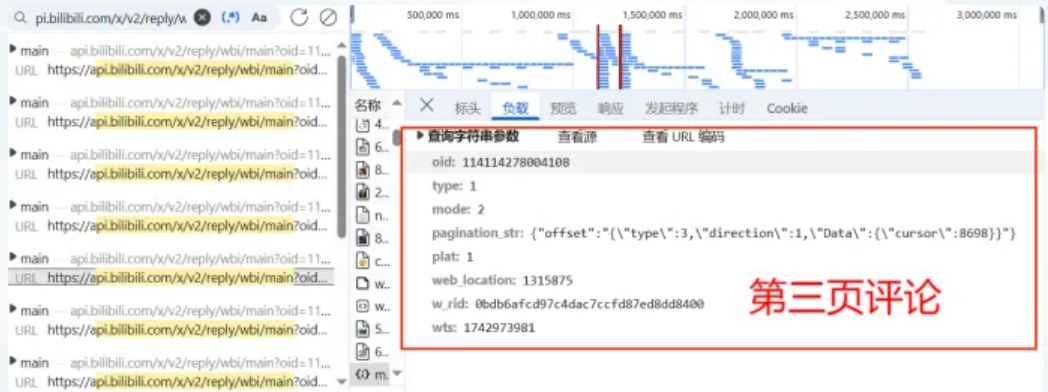
通过上面的图中的信息,可以发现pagination_str值在第一页时,默认值为{"offset":""}而后续页数都不同,其中从第二页,评论页的\"cursor\"值开始不同,为了寻找该值变化的规律,搜索不同数值,即8722的位置。
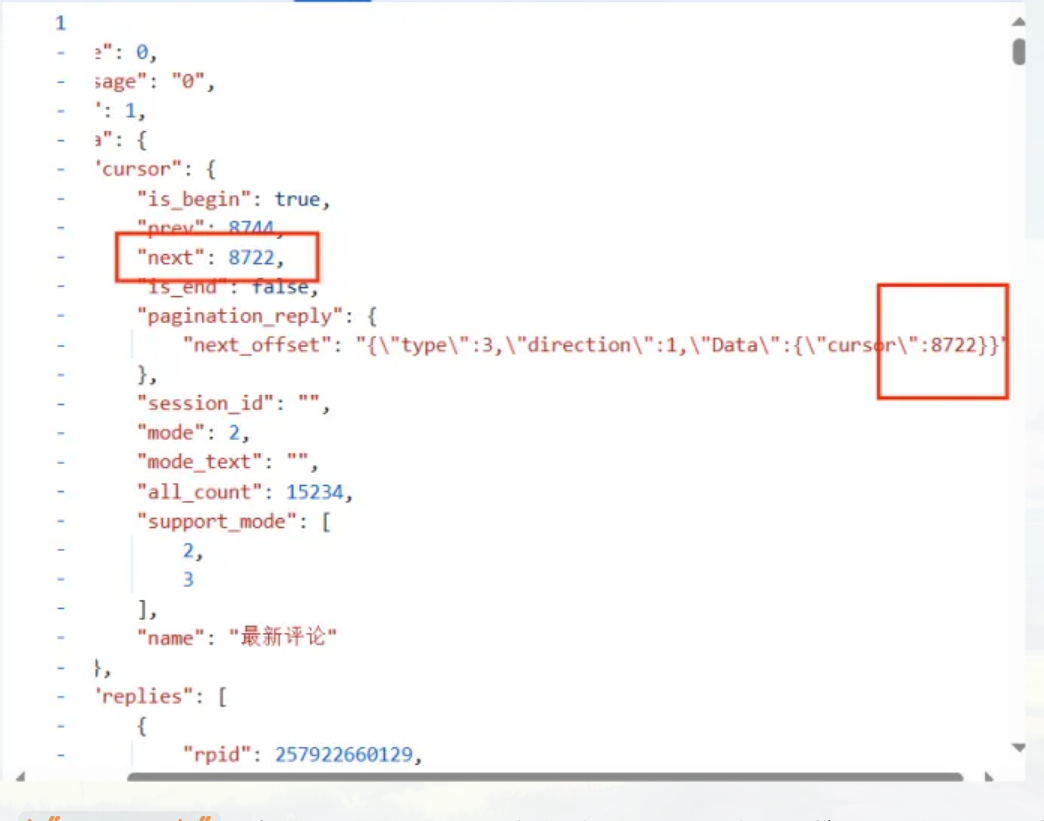
由此发现,所谓的\"cursor\"值都在上一页的JSON数据中。比如,获取了第一页,就可以获取第二页的\"cursor\",以此访问第二页的数据,然后继续获得第三页的\"cursor\",以此连接下去,最终获得所有页。
通俗的解释就是,前一页蕴含着指向下一页的“指针”。 代码大致如下:
.....
## 如果不是第一页
if pageID != '':
pagination_str = '{"offset":"{\\\"type\\\":3,\\\"direction\\\":1,\\\"Data\\\":{\\\"cursor\\\":%d}}"}' % pageID
## 如果是第一页
else:
pagination_str = '{"offset":""}'
.....
## 下一页的pageID
next_pageID = comment['data']['cursor']['next']
## 判断是否是最后一页了
if next_pageID == 0:
print(f"评论爬取完成!总共爬取{count}条。")
return
## 如果不是最后一页,则停0.5s(避免反爬机制)
else:
time.sleep(0.5)
print(f"当前爬取{count}条。")
start(bv, oid, next_pageID, count, csv_writer,is_second)7 :w_rid与MD5加密算法
w_rid的获取最为复杂,首先需要获取它的位置
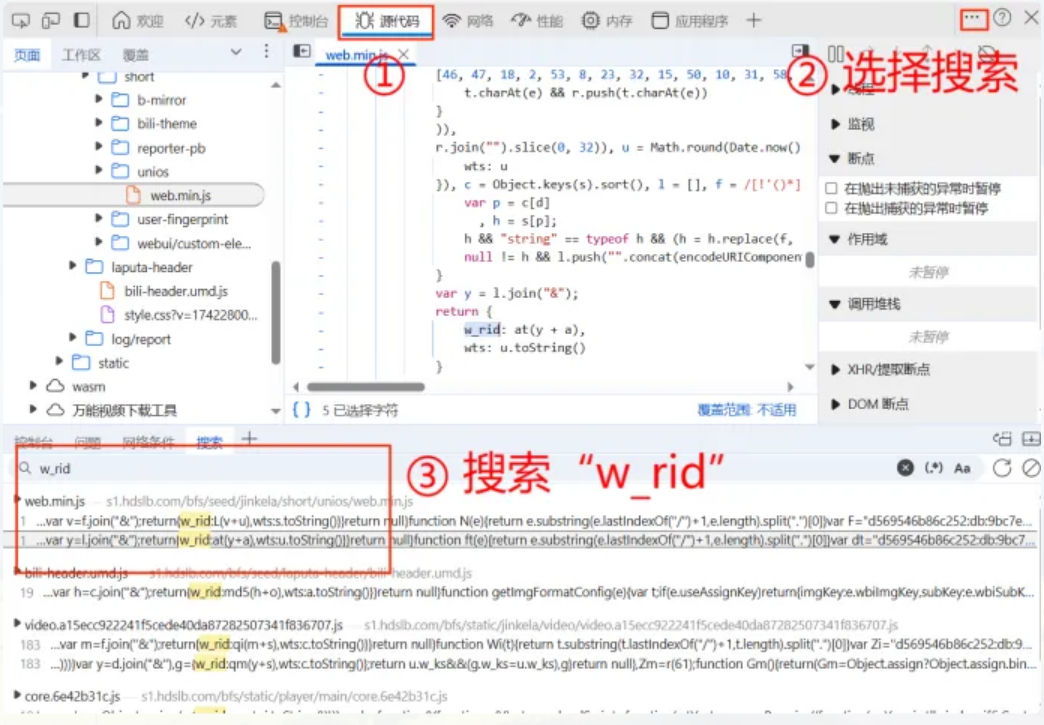
如图所示,它的结果来源于函数的计算,为了解出函数的具体功能以及函数中参数的内容,对这段代码进行断点测试。

断点后刷新页面,页面停止到该函数运行前
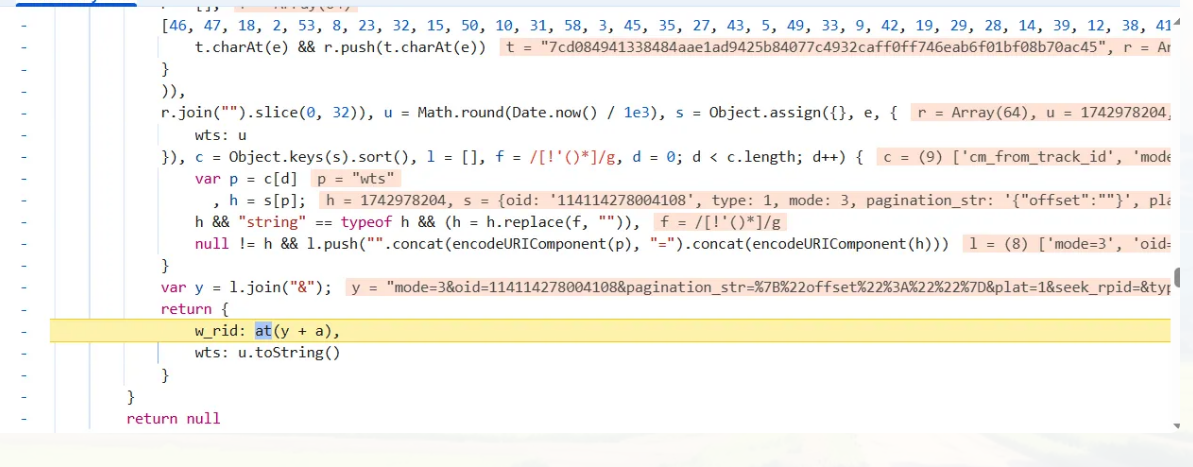
在控制台分别输入参数以及函数,观察输出结果

由此一切都解密出来了,y是几个上述参数以&拼接而来的字符串,而a是一个字符串常量,并且观察at()函数的运行结果,可以得出,它是一个MD5加密,返回y与a相加后的加密结果。
y:其他变量通过&相互拼接形成的字符串
a:加密参数,默认为'ea1db124af3c7062474693fa704f4ff8'
at():MD5加密算法,加密y与a
w_rid的加密过程如下
## MD5加密
md5_str='ea1db124af3c7062474693fa704f4ff8' ## 加密参数
code = f"mode={mode}&oid={oid}&pagination_str={urllib.parse.quote(pagination_str)}&plat={plat}&seek_rpid={seek_rpid}&type={type}&web_location={web_location}&wts={wts}" + md5_str
MD5 = hashlib.md5()
MD5.update(code.encode('utf-8'))
w_rid = MD5.hexdigest()四. 完整代码
import re
import requests
import json
from urllib.parse import quote
import pandas as pd
import hashlib
import urllib
import time
import csv
## 获取B站的Header
def get_Header():
with open('bili_cookie.txt','r') as f:
cookie=f.read()
header={
"Cookie":cookie,
"User-Agent":'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/134.0.0.0 Safari/537.36 Edg/134.0.0.0'
}
return header
## 通过bv号,获取视频的oid
def get_information(bv):
resp = requests.get(f"https://www.bilibili.com/video/{bv}/?p=14&spm_id_from=pageDriver&vd_source=cd6ee6b033cd2da64359bad72619ca8a",headers=get_Header())
## 提取视频oid
obj = re.compile(f'"aid":(?P<id>.*?),"bvid":"{bv}"')
oid = obj.search(resp.text).group('id')
## 提取视频的标题
obj = re.compile(r'<title data-vue-meta="true">(?P<title>.*?)</title>')
try:
title = obj.search(resp.text).group('title')
except:
title = "未识别"
return oid,title
## MD5加密
def md5(code):
MD5 = hashlib.md5()
MD5.update(code.encode('utf-8'))
w_rid = MD5.hexdigest()
return w_rid
## 轮页爬取
def start(bv, oid, pageID, count, csv_writer, is_second):
## 参数
mode = 2 ## 为2时爬取的是最新评论,为3时爬取的是热门评论
plat = 1
type = 1
web_location = 1315875
## 获取当下时间戳
wts = int(time.time())
## 如果不是第一页
if pageID != '':
pagination_str = '{"offset":"%s"}' % pageID
code = f"mode={mode}&oid={oid}&pagination_str={urllib.parse.quote(pagination_str)}&plat={plat}&type={type}&web_location={web_location}&wts={wts}" + 'ea1db124af3c7062474693fa704f4ff8'
w_rid = md5(code)
url = f"https://api.bilibili.com/x/v2/reply/wbi/main?oid={oid}&type={type}&mode={mode}&pagination_str={urllib.parse.quote(pagination_str, safe=':')}&plat=1&web_location=1315875&w_rid={w_rid}&wts={wts}"
## 如果是第一页
else:
pagination_str = '{"offset":""}'
code = f"mode={mode}&oid={oid}&pagination_str={urllib.parse.quote(pagination_str)}&plat={plat}&seek_rpid=&type={type}&web_location={web_location}&wts={wts}" + 'ea1db124af3c7062474693fa704f4ff8'
w_rid = md5(code)
url = f"https://api.bilibili.com/x/v2/reply/wbi/main?oid={oid}&type={type}&mode={mode}&pagination_str={urllib.parse.quote(pagination_str, safe=':')}&plat=1&seek_rpid=&web_location=1315875&w_rid={w_rid}&wts={wts}"
comment = requests.get(url=url, headers=get_Header()).content.decode('utf-8')
comment = json.loads(comment)
for reply in comment['data']['replies']:
## 评论数量+1
count += 1
if count % 1000 ==0:
time.sleep(20)
## 上级评论ID
parent=reply["parent"]
## 评论ID
rpid = reply["rpid"]
## 用户ID
uid = reply["mid"]
## 用户名
name = reply["member"]["uname"]
## 用户等级
level = reply["member"]["level_info"]["current_level"]
## 性别
sex = reply["member"]["sex"]
## 头像
avatar = reply["member"]["avatar"]
## 是否是大会员
if reply["member"]["vip"]["vipStatus"] == 0:
vip = "否"
else:
vip = "是"
## IP属地
try:
IP = reply["reply_control"]['location'][5:]
except:
IP = "未知"
## 内容
context = reply["content"]["message"]
## 评论时间
reply_time = pd.to_datetime(reply["ctime"], unit='s')
## 相关回复数
try:
rereply = reply["reply_control"]["sub_reply_entry_text"]
rereply = int(re.findall(r'\d+', rereply)[0])
except:
rereply = 0
## 点赞数
like = reply['like']
## 个性签名
try:
sign = reply['member']['sign']
except:
sign = ''
## 写入CSV文件
csv_writer.writerow([count, parent, rpid, uid, name, level, sex, context, reply_time, rereply, like, sign, IP, vip, avatar])
## 二级评论(如果开启了二级评论爬取,且该评论回复数不为0,则爬取该评论的二级评论)
if is_second and rereply !=0:
for page in range(1,rereply//10+2):
second_url=f"https://api.bilibili.com/x/v2/reply/reply?oid={oid}&type=1&root={rpid}&ps=10&pn={page}&web_location=333.788"
second_comment=requests.get(url=second_url,headers=get_Header()).content.decode('utf-8')
second_comment=json.loads(second_comment)
for second in second_comment['data']['replies']:
## 评论数量+1
count += 1
## 上级评论ID
parent=second["parent"]
## 评论ID
second_rpid = second["rpid"]
## 用户ID
uid = second["mid"]
## 用户名
name = second["member"]["uname"]
## 用户等级
level = second["member"]["level_info"]["current_level"]
## 性别
sex = second["member"]["sex"]
## 头像
avatar = second["member"]["avatar"]
## 是否是大会员
if second["member"]["vip"]["vipStatus"] == 0:
vip = "否"
else:
vip = "是"
## IP属地
try:
IP = second["reply_control"]['location'][5:]
except:
IP = "未知"
## 内容
context = second["content"]["message"]
## 评论时间
reply_time = pd.to_datetime(second["ctime"], unit='s')
## 相关回复数
try:
rereply = second["reply_control"]["sub_reply_entry_text"]
rereply = re.findall(r'\d+', rereply)[0]
except:
rereply = 0
## 点赞数
like = second['like']
## 个性签名
try:
sign = second['member']['sign']
except:
sign = ''
## 写入CSV文件
csv_writer.writerow([count, parent, second_rpid, uid, name, level, sex, context, reply_time, rereply, like, sign, IP, vip, avatar])
## 下一页的pageID
try:
next_pageID = comment['data']['cursor']['pagination_reply']['next_offset']
except:
next_pageID = 0
## 判断是否是最后一页了
if next_pageID == 0:
print(f"评论爬取完成!总共爬取{count}条。")
return bv, oid, next_pageID, count, csv_writer,is_second
## 如果不是最后一页,则停0.5s(避免反爬机制)
else:
time.sleep(0.5)
print(f"当前爬取{count}条。")
return bv, oid, next_pageID, count, csv_writer,is_second
if __name__ == "__main__":
## 获取视频bv
bv = "BV1ex7VzREZ8"
## 获取视频oid和标题
oid,title = get_information(bv)
## 评论起始页(默认为空)
next_pageID = ''
## 初始化评论数量
count = 0
## 是否开启二级评论爬取,默认开启
is_second = True
## 创建CSV文件并写入表头
with open(f'{title[:12]}_评论.csv', mode='w', newline='', encoding='utf-8-sig') as file:
csv_writer = csv.writer(file)
csv_writer.writerow(['序号', '上级评论ID','评论ID', '用户ID', '用户名', '用户等级', '性别', '评论内容', '评论时间', '回复数', '点赞数', '个性签名', 'IP属地', '是否是大会员', '头像'])
## 开始爬取
while next_pageID != 0:
bv, oid, next_pageID, count, csv_writer,is_second=start(bv, oid, next_pageID, count, csv_writer,is_second)总结
这款高性能 Bilibili 评论采集工具旨在提供完整、稳定、易用的视频评论数据获取方案。要部署这个应用那肯定少不了一台高性能的服务器,让你更快速、更高效的使用,博主这边给大家推荐一个便宜又速度快的海外云服务器 VMRack,他家有三条线路分别是 三网精品(电信: CN2 GIA/联通: CU9929/移动: CMIN2)、三网优化(电信163/联通10099/移动CMI 回程: 联通10099)、国际BGP,能满足绝大多数个人或中小企业的日常使用需求并且够买不需要实名和ICP备案。现在国际BGP的价格低至3.66$每月起!!!!